D2GRs2 方法对比
1# 成本对比
| GRs | DLRMs(du) | 备注 | |
|---|---|---|---|
| 参数量 | 最大1.5万亿 | 精排1.2亿 | |
| 样本量 | 1000亿 | 1亿/天 | 追3个月100亿的样本 1倍 |
| 运算量 :排序 |
和传统DLRM持平 |
1万倍 0.3GFLOPS * 样本1亿/天 原文对比的DLRM计算量也大 DLRM缩放到2000亿都有提升 |
|
| 运算量 :召回 |
略超过DLRM |
100倍 | |
| 序列长度 | 最长8192 | 最长200 | |
| 特征维度 | 序列+用户信息 | 序列+行为统计 场景商品上下文 |
千川 行为统计 最长半年 时间半年 95%用户半年点击商品<122 75%用户半年点击商品>185 长度200 有用户半年前行为的占18% |
| 训练资源 | 64-256 H100 | 2 L20? | 开源数据运行需要29G GPU 训练的最大序列长度是200 |
2# 效果对比
| GRs | DLRMs(du) | |
|---|---|---|
| 排序 | E-Task +12.4% C-Task +4.4% |
1000个dense特征 50个稀疏特征 MoE、DCN、DIN,residual connection等 |
| 替代召回 | E-Task +5.1% C-Task +1.9% |
双塔模型,in-batch and out-of-batch采样 特征包括id、稀疏特征等。 通过残差连接MLP将输入压缩成user和item表征 |
| 新增召回 | E-Task +6.2% C-Task +5.0% |
3# 样本对比
| 样本 | GRs | DLRMs | 备注 |
|---|---|---|---|
| 数据量 | 曝光量*采样 | 曝光量 | 对第i个用户按比例 where 每次曝光20 ni+20 新用户 采样比例 |
| 格式 | 用户基础 曝光序列 行为序列 时间序列 |
用户基础 点击序列 商品信息 场景统计 用户统计 商品统计 上下文 |
| 特征 | 类型 | GRs | DLRMs | 备注 |
|---|---|---|---|---|
| 用户基础 | sparse | 相同 | 相同 | 用户年龄、性别等 |
| 行为序列 | sparse | 曝光序列 时间排序 对应行为 |
交互过的序列为主 | |
| 行为统计 | dense | 行为序列包含 target attention sideinfo序列? |
各种统计 时间(1d/7d/6m) 维度(brand/cate) |
|
| 商品信息 | sparse |
side info包含 |
商品属性信息 |
|
| 商品统计 | dense | 放弃? | 商品全场景效率统计 | |
| 场景统计 | dense | side info加场景? 否则只能放弃 |
场景内效率统计 | |
| 上下文 | sparse | 放弃 | 上下文特征 | position、time |
4# 序列信息对比
行为序列中超过半年的有
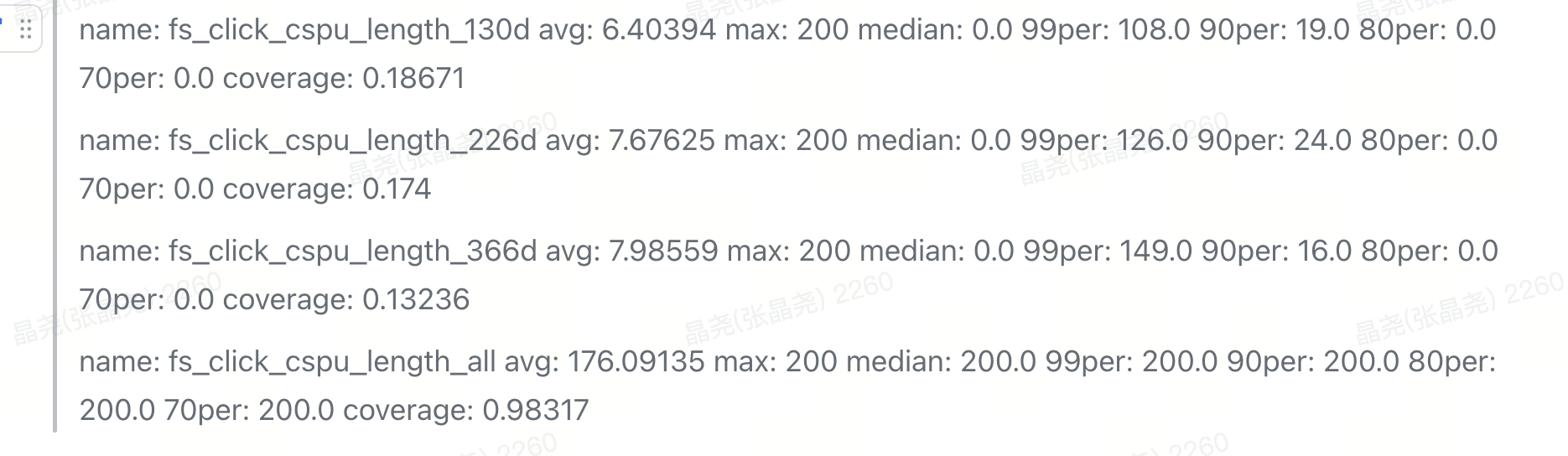
半年-用户点击商品-去重 95%的点击长度不到122
| nrow | avg_clk_cspu_set_size | max_size | min_size |
|---|---|---|---|
| 1 | 1.0 | 1 | 1 |
| 2 | 1.0 | 1 | 1 |
| 3 | 1.0 | 1 | 1 |
| 4 | 1.6253557589434156 | 2 | 1 |
| 5 | 2.0 | 2 | 2 |
| 6 | 2.6950291427980324 | 3 | 2 |
| 7 | 3.313933057280783 | 4 | 3 |
| 8 | 4.238800094951729 | 5 | 4 |
| 9 | 5.361683213430271 | 6 | 5 |
| 10 | 6.622790690820511 | 7 | 6 |
| 11 | 8.41926615503423 | 9 | 7 |
| 12 | 10.545792688629385 | 12 | 9 |
| 13 | 13.276215569603133 | 15 | 12 |
| 14 | 16.87280245368841 | 19 | 15 |
| 15 | 21.749590458604658 | 25 | 19 |
| 16 | 28.649816866277366 | 33 | 25 |
| 17 | 39.009800542981566 | 46 | 33 |
| 18 | 56.24465086705472 | 69 | 46 |
| 19 | 91.0510507136846 | 122 | 69 |
| 20 | 263.25581251145314 | 21684 | 122 |
| 半年-用户曝光未点击-序列 |
| nrow | avg_cspu_set_size | max_cspu_set_size | min_cspu_set_size |
|---|---|---|---|
| 1 | 1.0 | 1 | 1 |
| 2 | 1.8874791442851482 | 3 | 1 |
| 3 | 3.0 | 3 | 3 |
| 4 | 3.735776016424266 | 5 | 3 |
| 5 | 5.536095589581591 | 6 | 5 |
| 6 | 7.554326333754676 | 9 | 6 |
| 7 | 10.44569675551624 | 12 | 9 |
| 8 | 14.494199592775852 | 17 | 12 |
| 9 | 20.1131525752258 | 24 | 17 |
| 10 | 28.01962242424109 | 33 | 24 |
| 11 | 39.07454510827324 | 46 | 33 |
| 12 | 54.68846426199999 | 64 | 46 |
| 13 | 76.89072061320397 | 91 | 64 |
| 14 | 108.68811584108668 | 129 | 91 |
| 15 | 155.11521319082792 | 185 | 129 |
| 16 | 225.09093165876791 | 272 | 185 |
| 17 | 336.8879388625474 | 415 | 272 |
| 18 | 534.0983758167371 | 685 | 415 |
| 19 | 956.484335509485 | 1348 | 685 |
| 20 | 3110.240310796316 | 231863 | 1348 |
原文:
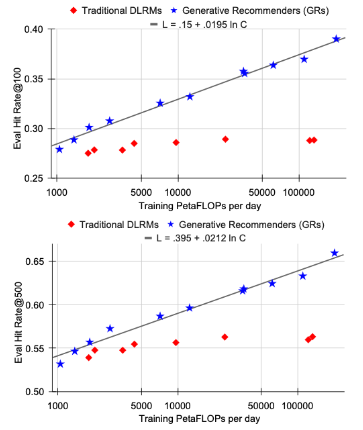
在低计算资源条件下,由于手工制作的特征,传统DLRM排序可能优于GRs,这证实了特征工程在传统DLRM中的重要性。(10^5petaflops 持平)。
缩放率生效,GRs1.5万亿个参数模型,而DLRMs的性能在约2000亿个参数时饱和。
我们对模型进行了100B以上的训练(相当于DLRM),每个作业使用64-256个H100。
-
召回
就可以持平DLRMs
-
排序
才持平DLRMs
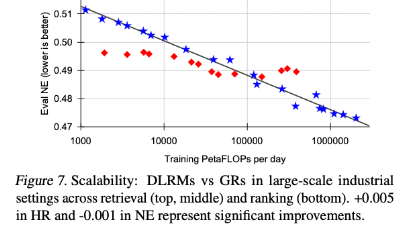
最终,我们所有主要的指标,包括检索任务中的Hit Rate@100和Hit Rate@500,以及排名任务中的NE,只要给定适当的超参数,都会根据所使用的计算量呈现出幂律缩放。
我们在三个数量级上观察到这一现象,一直到我们能够测试的最大模型(具有8192的序列长度、1024的嵌入维度和24层的HSTU),此时我们使用的总计算量(标准化为一年的使用量,因为我们采用的是标准的流式训练设置)接近于GPT-3(Brown等人,2020年)和LLaMa2(Touvron等人,2023b)所使用的总训练计算量,如图1所示。
在合理的范围内,确切的模型超参数相比于应用的总训练计算量来说,其影响较小。
与语言建模不同,在推荐系统中序列长度起着更加重要的作用,需要同时增加序列长度和其他参数。
这可能是我们提出方法的最重要优势,因为我们首次展示了大型语言模型的扩展法则也可能适用于大规模推荐系统。
- TFLOPS: 万亿次每秒
- PFLOPS: 千万亿次每秒
FLOPs 是floating point of operations的缩写,是浮点运算次数,可以用来衡量算法/模型复杂度。
MFLOPS(megaFLOPS)等于每秒一百万(=10^6)次的浮点运算
GFLOPS(gigaFLOPS)等于每秒十亿(=10^9)次的浮点运算
TFLOPS(teraFLOPS)等于每秒一万亿(=10^12)次的浮点运算(1太拉)
PFLOPS(petaFLOPS)等于每秒一千万亿(=10^15)次的浮点运算
EFLOPS(exaFLOPS)等于每秒一百京(=10^18)次的浮点运算
ZFLOPS(zettaFLOPS)等于每秒十万京(=10^21)次的浮点运算
样本量


Loss

序列构建